
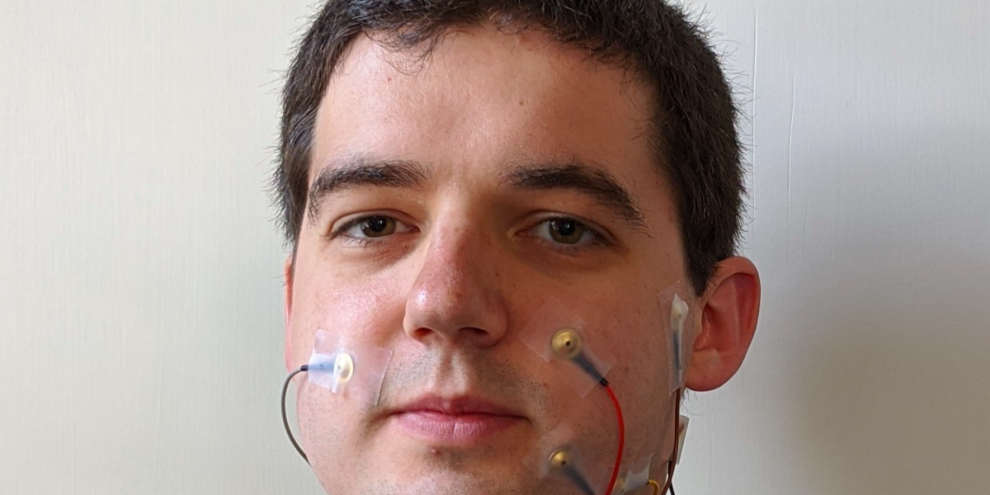
UC Berkeley researchers say they are the first to train AI using using silently mouthed words and sensors that collect muscle activity. Silent speech is detected using electromyography (EMG), with electrodes placed on the face and throat. The model focuses on what researchers call digital voicing to predict words and generate synthetic speech.
Researchers believe their method can enable a number of applications for people who are unable to produce audible speech and could support speech detection for AI assistants or other devices that respond to voice commands.
“Digitally voicing silent speech has a wide array of potential applications,” the team’s paper reads. “For example, it could be used to create a device analogous to a Bluetooth headset that allows people to carry on phone conversations without disrupting those around them. Such a device could also be useful in settings where the environment is too loud to capture audible speech or where maintaining silence is important.”
Another example of AI that can capture words from silent speech — lip-reading AI — can power surveillance tools or support use cases for people who are deaf.
For their silent speech prediction, the UC Berkeley researchers used an approach “where audio output targets are transferred from vocalized recordings to silent recordings of the same utterances.” A WaveNet decoder is then used to generate audio speech predictions.
Compared to a baseline trained with vocalized EMG data, the approach delivers a 64% to 4% decline in word error rates in transcriptions of sentences from books and an error reduction of 95% from the baseline. To fuel additional work in this area, the researchers open-sourced a dataset of nearly 20 hours of facial EMG data.
A paper about the model titled “Digital Voicing of Silent Speech” by David Gaddy and Dan Klein received the Best Paper award at the Empirical Methods in Natural Language Processing (EMNLP) event held online last week. The company Hugging Face received the Best Demo Paper award from organizers for its work on the open source Transformers library. In other EMNLP works, members of the Masakhane open source project for translating African languages published a case study on low-resourced machine translation, and researchers from China introduced a sarcasm detection model that achieved state-of-the-art performance on a multimodal Twitter dataset.
This content was originally published here.
EL 2 DE JUNIO DEL 2024 VOTA PARA MANTENER
TU LIBERTAD, LA DEMOCRACIA Y EL RESPETO A LA CONSTITUCIÓN.

VOTA POR XÓCHITL






Comentarios