En 1951, Marvin Minsky, entonces estudiante en la universidad de Harvard, tomado de las observaciones de la conducta de los animales a tratar de diseñar una máquina inteligente. El dibujo en la obra del fisiólogo Ivan Pavlov, quien se hizo famoso por utilizar perros para mostrar cómo los animales aprenden a través de castigos y recompensas, Minsky creado un equipo que podría aprender constantemente a través de similar refuerzo para resolver un laberinto virtual.
En el momento, los neurocientíficos aún tenía que averiguar los mecanismos en el cerebro que permiten a los animales para aprender de esta manera. Pero Minsky todavía era capaz de flojos imitar el comportamiento, con lo que el avance de la inteligencia artificial. Varias décadas más tarde, como el aprendizaje por refuerzo continuó maduro, que a su vez ayudó al campo de la neurociencia descubrir los mecanismos de alimentación a un ciclo virtuoso de progreso entre los dos campos.
En un artículo publicado hoy en la Naturaleza, DeepMind, Alfabeto AI filial, se ha utilizado una vez más lecciones de aprendizaje por refuerzo para proponer una nueva teoría acerca de los mecanismos de recompensa dentro de nuestro cerebro. La hipótesis, apoyada por la inicial de los resultados experimentales, no sólo podría mejorar nuestra comprensión de la salud mental y la motivación. También podría validar la dirección de la corriente de IA investigación hacia la construcción de la más parecida a la humana inteligencia en general.
regístrese para El Algoritmo — la inteligencia artificial, desmitificado,
En un nivel alto, el aprendizaje por refuerzo de la siguiente manera el conocimiento derivado de perros de Pavlov: es posible enseñar a un agente de dominar el complejo, la novela de tareas a través de sólo comentarios positivos y negativos. Un algoritmo comienza el aprendizaje de una tarea asignada por azar la predicción de que la acción podría ganar una recompensa. A continuación, toma la acción, observa la verdadera recompensa, y ajusta su predicción, basada en el margen de error. A lo largo de millones o incluso miles de millones de ensayos, el algoritmo de predicción de errores converge a cero, momento en el que sabe precisamente qué acciones tomar para maximizar su recompensa y así completar su tarea.
resulta Que el sistema de recompensa del cerebro funciona de la misma manera—un descubrimiento realizado en la década de 1990, inspirada por el refuerzo de los algoritmos de aprendizaje. Cuando un ser humano o animal está a punto de realizar una acción, sus neuronas de dopamina hacer una predicción acerca de la recompensa esperada. Una vez que la verdadera recompensa es recibido, que, a continuación, disparar una cantidad de dopamina que se corresponde con el error de predicción. Una mejor recompensa que espera que desencadena una fuerte liberación de dopamina, mientras que la peor de la recompensa que espera que suprime la química de la producción. La dopamina, en otras palabras, sirve como una señal de corrección, diciendo que las neuronas para ajustar sus predicciones hasta que convergen a la realidad. El fenómeno, conocido como error de predicción de recompensa, funciona como un refuerzo-el algoritmo de aprendizaje.
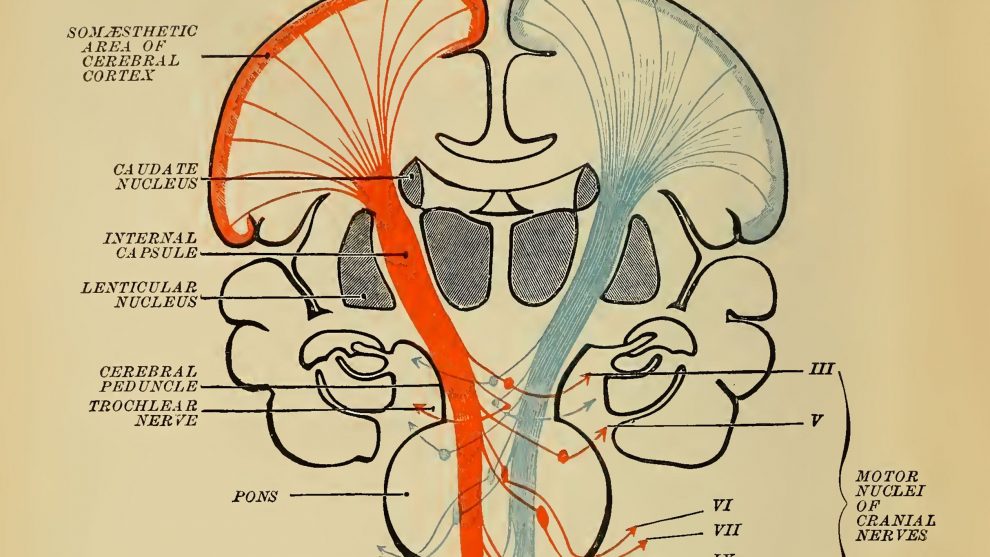
DeepMind del nuevo documento se basa en la estrecha relación entre estos naturales y artificiales de mecanismos de aprendizaje. En 2017, sus investigadores introdujeron una mejora de los sistemas de refuerzo de algoritmo de aprendizaje que se ha desbloqueado cada vez más impresionantes de rendimiento en diversas tareas. Ahora se cree que este nuevo método podría ofrecer una manera aún más precisa explicación de cómo la dopamina trabajo de las neuronas en el cerebro.
Específicamente, la mejora de los cambios de algoritmo de la forma en que se predice recompensas. Mientras que el viejo enfoque estimado de recompensas como un número único para la igualdad de la media de los resultados esperados—el nuevo enfoque que se les representa con mayor precisión como una distribución. (Piensa por un momento acerca de una máquina de ranura: se puede ganar o perder siguientes algunos de distribución. Pero en ningún caso sería usted alguna vez ha recibido el promedio de los resultados esperados.)
La modificación se presta a una nueva hipótesis: ¿las neuronas de la dopamina también predecir las recompensas en la distribución de la misma manera?
Para probar esta teoría, DeepMind se asoció con un grupo en la universidad de Harvard para observar el comportamiento de las neuronas de dopamina en ratones. Que establece los ratones en una tarea y recompensado con base en la tirada de dados, la medición de los patrones de disparo de sus neuronas de dopamina en todo. Encontraron que cada neurona libera diferentes cantidades de dopamina, lo que significa que todos habían predicho los diferentes resultados. Mientras que algunos eran demasiado “optimista” predicción de la mayor de las recompensas que recibe, otros eran más “pesimista” lowballing la realidad. Cuando los investigadores asignan a cabo la distribución de las predicciones, es seguido de cerca la distribución real de las recompensas. Estos datos ofrece pruebas convincentes de que el cerebro, de hecho, utiliza la distribución de la recompensa predicciones para fortalecer su algoritmo de aprendizaje.
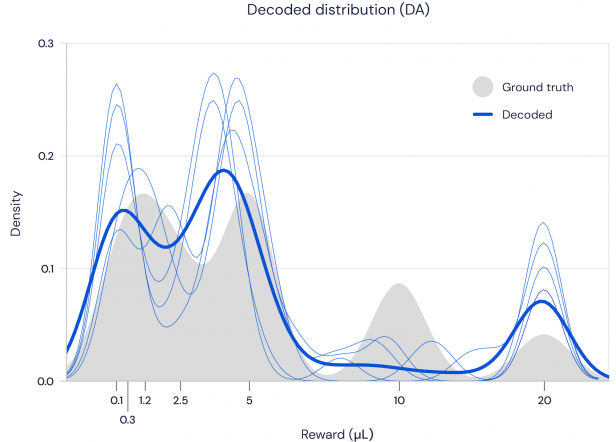
“Esta es una buena extensión de la noción de la dopamina de la codificación del error de predicción de recompensa”, escribió Wolfram Schultz, un pionero en las neuronas de dopamina comportamiento que no estaba involucrado en el estudio, en un correo electrónico. “Es increíble cómo esta muy simple la dopamina respuesta predecible de la siguiente manera intuitiva patrones de biológicos básicos de los procesos de aprendizaje que ahora se están convirtiendo en un componente de la IA.”
El estudio tiene implicaciones para la AI y la neurociencia. En primer lugar, se valida la distribución de refuerzo de aprendizaje como un camino prometedor para más avanzadas AI capacidades. “Si el cerebro está utilizando, es probablemente una buena idea,” dijo Matt Botvinick, DeepMind director de investigación de la neurociencia y uno de los autores principales en el papel, durante una rueda de prensa. “Nos dice que esta es una técnica computacional que se puede escalar en situaciones del mundo real. Va a encajar bien con otros procesos computacionales.”
en Segundo lugar, podría ofrecer una importante actualización para uno de los canónica de las teorías de la neurociencia acerca de los sistemas de recompensa en el cerebro, que a su vez podría mejorar nuestra comprensión de todo, desde la motivación para la salud mental. Lo que podría significar, por ejemplo, para tener “pesimista” y “optimista” las neuronas de la dopamina? Si el cerebro de forma selectiva escuchado sólo uno o el otro, podría conducir a desequilibrios químicos y de inducir a la depresión?
Fundamentalmente, por más de decodificación de los procesos en el cerebro, los resultados también arrojan luz sobre lo que crea la inteligencia humana. “Esto nos da una nueva perspectiva sobre lo que está pasando en nuestro cerebro durante la vida cotidiana,” Botvinick, dijo.
This content was originally published here.
EL 2 DE JUNIO DEL 2024 VOTA PARA MANTENER
TU LIBERTAD, LA DEMOCRACIA Y EL RESPETO A LA CONSTITUCIÓN.

VOTA POR XÓCHITL